







眼科画像に基づく糖尿病のスクリーニング(1)

眼は生活習慣病の窓で、眼底血管病変及び角膜の細い神経線維を直接観察できる。検査手法としては、非侵襲的でかつ短時間で患者への負担が少なく、繰り返し検査を行うことができる。さらに、糖尿病の早期発見と全身合併症を把握することが可能である。
今回のテーマは、糖尿病スクリーニングに機械学習手法を用いることにより、医者がより効率的に眼科画像を解析することができることを、技術的な参考情報としてご紹介していきたい。
まずは糖尿病の現状について抑えておきたい。2019年11月14日の世界糖尿病デーに、国際糖尿病連合(IDF)の発表した「IDF 糖尿病アトラス 第9版」(9th Edition of IDF Diabetes Atlas)によると、世界の糖尿病人口は爆発的に増え続けており、2019年時点で糖尿病有病者数は4億6,300万人(日本の成人の糖尿病有病者数が739万人)になることが明らかになった。
糖尿病有病者数は、有効な対策を施さないと、2030年までに5億7,800万人に、2045年までに7億人に増加すると予測されている。
糖尿病は合併症(神経の障害と網膜症と腎臓の障害) を起こすことが知られて、 自覚症状がなくても、見えないところで合併症が進行して、2019年には糖尿病が原因で8秒に1人が糖尿病のために亡くなって、糖尿病関連の医療費は約83兆円(日本は2.6兆円)であった。
糖尿病は初期の段階では自覚症状の乏しい病気なので、診断を受けていない人も多い。そのため、すべてのタイプの糖尿病を早期発見し、糖尿病合併症を予防し、2型糖尿病を予防するための対策が必要である。その対策方法の一つが、眼底画像を用いた解析である。
眼底画像分類‐ラベリング
眼底画像を用いた解析方法に、眼底画像分類がある。眼底画像分類とは、機械学習やディープラーニングモデルにおいて、軽症単純網膜症、増殖前網膜症に基づき分類する処理方法のことを示している。「教師あり学習」では、ラベル付けされたデータセットを用いて、モデルを学習させる。「教師なし学習」では、事前のラベル付けはせず、眼底画像データが持つ特徴量の分布に基づいて、複数のクラスに画像を分類してあるが、医用画像のほとんどの学習は教師あり学習(Supervised Learning))と半教師あり学習(Semi-Supervised Learning)で行うことが一般的である。
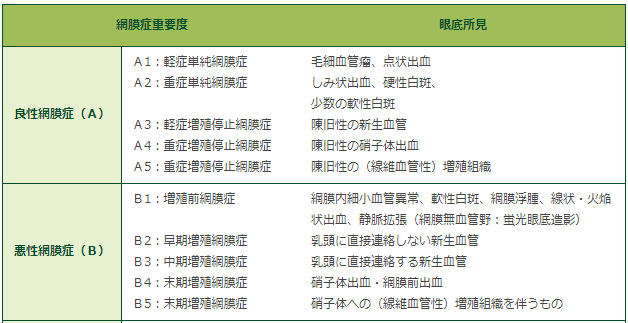
網膜症重要度と眼底初見について
(出典:福田 雅俊:糖尿病網膜症の病期分類。糖尿病と眼科診療 堀 貞夫 編 117-125, 1991、金原出版)
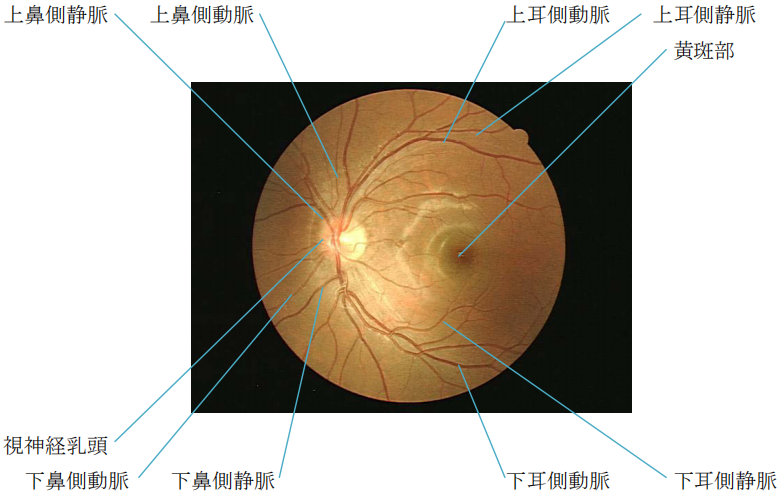
正常な網膜
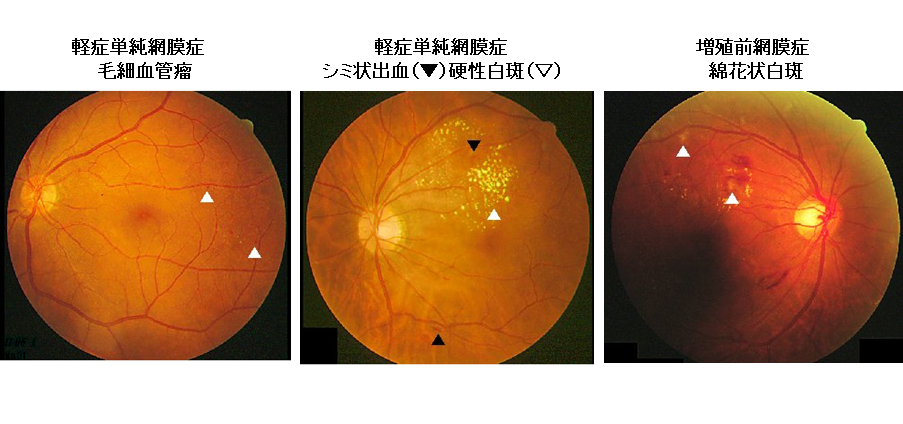
ラベリングデータの例
スクリーニングツール(例)
分類回帰モデルはサポートベクターマシーン(Support Vector Machine; SVM)を利用し、回帰によって分類する手法で、少量データ(2000枚のラベル付け眼底画像)でも高い精度で分類することができる。
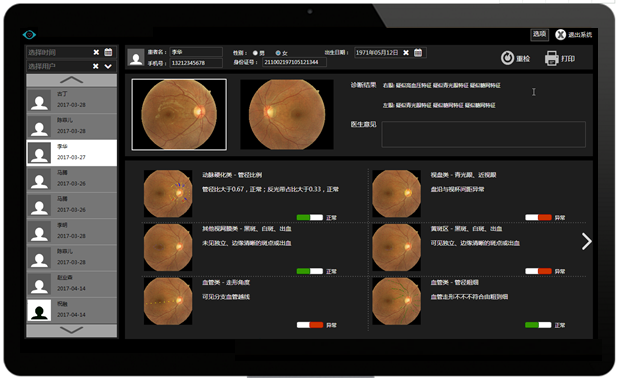
このように糖尿病のスクリーニングは、眼底カメラで撮った眼底画像を解析して実現が可能であり、非侵襲的でかつ短時間で患者への負担が少なく、さらに、少量な眼底画像のラベリングでも良い敏感度(sensitivity)と特異度( specificity)および有効度 (efficiency)が得ることができる。
さらに高いパフォーマンスのスクリーニングをするためには、大量の眼底画像データと少量なデータラベリングで深層学習手法(Deep Learning)を用いて実現が可能であり、医者にとって、注意深く忠実な助手としての利用が期待できる。次回のBlogでは、深層学習を用いた高いパフォーマンスのスクリーニングについてご紹介したい。
Blog投稿者
ストラクチュアルライン株式会社
李 徳衡






この記事へのコメントはありません。